It has already been two weeks since we opened registration for exhibitors in our forthcoming virtual showcase. Since then we have have been asked a variety of good questions regarding how our showcase operates and what you can do with it. Anticipating still more questions to come, I thought it might be useful to compile and answer a list of frequently asked questions (FAQs) that addressed many of the things our exhibitors, current and future, may want to know.
The list that Al and I came up with will be found below. If you have any other questions that have so far been overlooked please don’t hesitate to send them on. An FAQ Chapter 2 will surely follow.
FAQs For Virtual Showcase Exhibitors
Is there a discount for viaLibri subscribers? How do I make sure I qualify?
Yes, there is a 20% discount on all registration fees for viaLibri Premium Services subscribers. If you are a subscriber and you are signed in to viaLibri with the correct account then this discount will be applied automatically when you register for the showcase.
Can I increase my item count after I’ve signed up?
Yes. You can upgrade at any point until 48 hours before the showcase opens. All you will need to pay is the difference between the price of package you currently have and the price of the package you’re upgrading to.
See our help page for more details on how to do this.
Can I replace items once they’ve sold?
No. Once the showcase opens you will not be able to replace any items that have sold. You will be able to remove an item from sale if needed, but you will not be able to substitute a new item in its place.
Does Libribot also look for matches that appear in viaLibri Virtual Showcases?
Yes, the viaLibri Virtual Showcase is fully integrated into the rest of the viaLibri system.
Libribot is our wants matching service. Over 175,000 sets of search criteria have been saved in our database by our registered users, and every one of them will be checked against the listings in the showcase. Any users whose wants match items in the showcase case will be emailed a list of those items just before the showcase opens.
Normally there are limits on how many wants are searched per day for each user, depending on subscription level. We are waiving those limits for the showcase, so all wants will be checked against showcase items, regardless of subscription level.
Are there any limits on the number or size of images that can be uploaded?
Not that you’ll notice, no. You can add up to 100 images for each item, and each image can be up to 50MB in size. As long as you’re uploading normal JPEG photo files you shouldn’t have any problems.
Can I import items from my own website?
Yes. If your website listings are already included in viaLibri’s search results via our Harvest service then they can easily be copied over to the showcase. See our help page for instructions on how to do this.
How do payments for items in the showcase work?
viaLibri will not take any payments as part of the Virtual Showcase checkout. When someone buys an item from the showcase you will receive an email notifying you of the purchase. It is then your responsibility to get in touch with the buyer in order to specify the final postage charges and arrange payment.
Will buyers be able to reserve items?
Yes, buyers will be able to reserve items by clicking a button on the item page. This reservation will only last for 20 minutes: long enough for them to do some further research, but short enough that it shouldn’t get in the way of another sale if they’re not a serious customer.
Exhibitors can also reserve their own items (i.e. put them on hold) via the Exhibitor’s Dashboard. There is no time limit on these reservations.
When do I have to add my items by?
All items must be added 48 hours before the start of the showcase. After this point you will still be able to edit items and add images, but you will not be able to add new items.
Will items still be visible after they’ve sold?
Yes, items are still visible in the showcase once they have been sold. They will be clearly marked as “Sold” and their price will be hidden.
Can I set the order that items are shown on my profile page?
Yes. Once you’ve added your items in the Exhibitor’s Dashboard you can drag them up and down to set the order of items. These changes are saved automatically so there’s no need to press a button once you’re done.
How many categories or tags can you assign to each item?
There is no limit. You can use as many categories as you need to effectively describe your items.
What can I do if my item doesn’t belong in any of the existing categories?
You can easily create your own more useful categories and add them to the large selection already provided.
Do item listings include the name of the exhibitor?
Yes. Every item found when searching or browsing will have its seller clearly identified.
Can the Showcase translate items into foreign languages?
Yes. Located at the bottom of each item page there is a “translate” link which can translate item descriptions between 33 different languages.
Does the Showcase convert prices into foreign currencies?
Yes. Prices can be displayed in 13 different currencies.
To browse all the items in the showcase do I have to view each exhibitor’s items separately?
No. One click is enough to browse all items. To facilitate browsing, those results can then be sorted by year of publication, price, author, title or exhibitor.
Can descriptions of items of interest be saved for later reference?
Yes. On each item page there is a link labelled “Add to clipboard.” Clicking this link will save the item to your viaLibri “clipboard” where you can easily find it again later, even after the showcase has closed.
Can items be purchased directly from exhibitors without using the showcase checkout form?
Yes. You do not have to make a purchase using the showcase checkout form. However, if you know that you want to buy something it is to your advantage that the item be marked quickly as sold so that no one else can buy it before your order has been received by the exhibitor.
Register as an exhibitorLearn more



 added to the count and began including books and ephemera from Getman’s Virtual Book Fairs – the oldest, largest and best known virtual book fair platform.
added to the count and began including books and ephemera from Getman’s Virtual Book Fairs – the oldest, largest and best known virtual book fair platform.
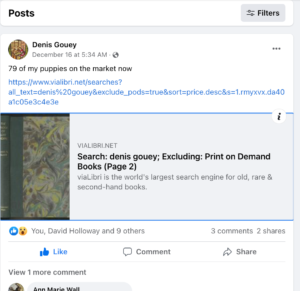 well-known bookbinder from Connecticut. Naturally, he is interested in promoting his skills on the internet. You can find him on Facebook where, on Friday, he published a post that links to a viaLibri search result listing all the books on viaLibri that match on the keyword “Denis Gouey”. As a result, anyone visiting him on facebook can click on this link and see pictures of lots of books bound by him and currently for sale online.
well-known bookbinder from Connecticut. Naturally, he is interested in promoting his skills on the internet. You can find him on Facebook where, on Friday, he published a post that links to a viaLibri search result listing all the books on viaLibri that match on the keyword “Denis Gouey”. As a result, anyone visiting him on facebook can click on this link and see pictures of lots of books bound by him and currently for sale online.